The Hanabi Challenge: A New Frontier for AI Research¶
Bard, Foerster, Chandar, et al.
presented by Albert Orozco Camacho
Click me to go to the article!
Motivation¶
In the context of reinforcement learning (RL)...
- the research community is constantly looking to better ways of assessing performance;
- typically, games like chess, go, or StarCraft serve for this means
Nevertheless, such games just offer testing:
- competitive settings
- zero-sum evaluation schemes
- individualistic policies that follow an equilibrium
Yet, games, in general, need many more abilities
What are we missing?¶
- A cooperative setting
- Imperfect information
- Assess restricted communication settings
- Communicating extra information implicitly (a form of reasoning)
The Hanabi Card Game¶
- Two to Five player game, similar to a cooperative solitarie
- Each card depicts a rank $\in \{1,2,3,4,5\}$ and colour (red, green, blue, yellow, white).
- Deck has a total of 50 cards, 10 of each color:
- three $1$s
- two $2$s
- two $3$s
- two $4$s
- one $5$s
- Players can only see their partners' hands
GOAL: Play cards to form five consecutively ordered stacks
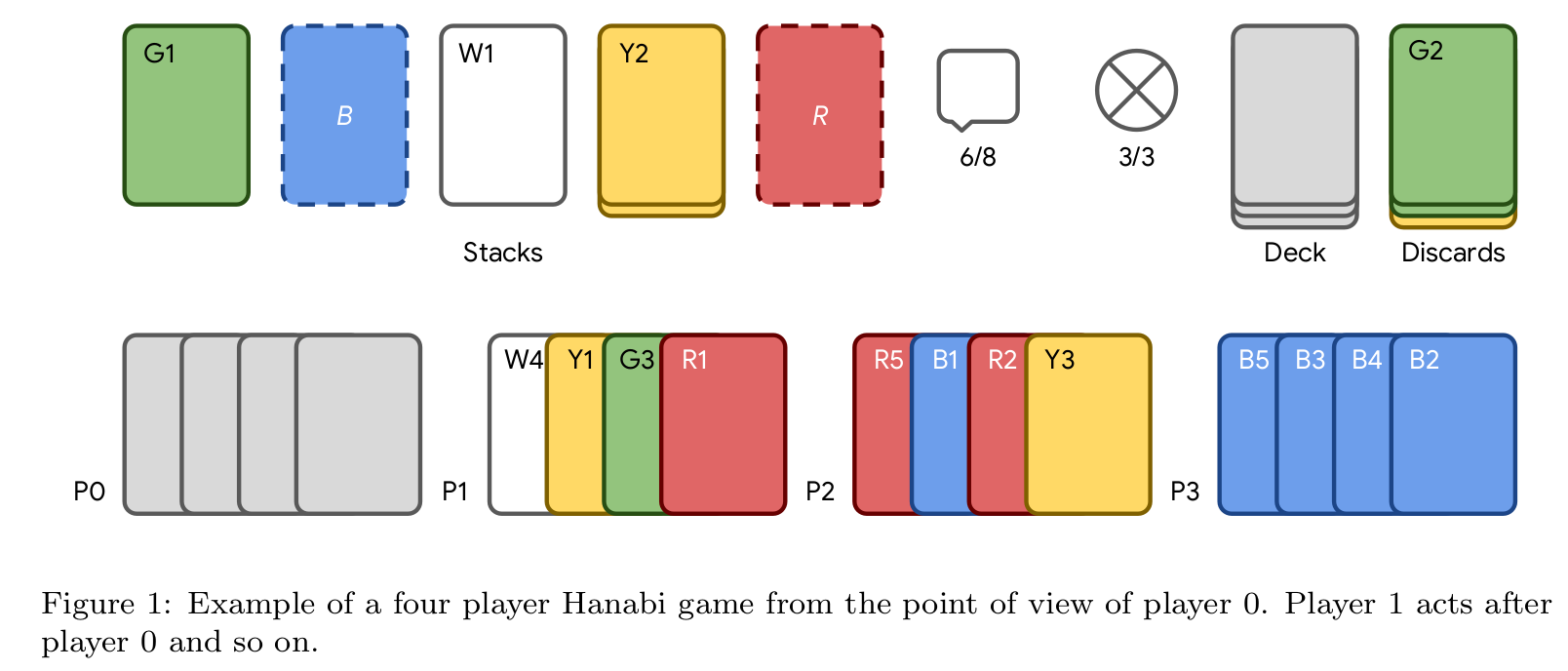
Players take turns doing one of three actions:
Giving a hint
The active player tells any other player a clue about the content of their hand. Hints are limited by information tokens (8 total)
The active player can discard a card from their hand, whenever there are < 8 information tokens
Such player then, has to draw a new card from the deck and an information token is recovered
Pick a card and play it
- Successful play: if the played card is the next in the sequence of its color
- Unsucessful play the played card is discarded and the group loses one life
- Players receive an extra information token if a stack is completed
Game Over
- Players complete all five stacks (perfect game with score = 25)
- Players consume all their lives or after drawing last card of deck (score equals to the sum of all the card numbers in the stacks)
Paper Contributions¶
- Motivate the ML (RL) research community to address a problem that requires
- learning implicit incentives
- theory of mind
- imperfect information
- Present an Open Source Environment, inspired on the OpenAI Gym
- Benchmark current RL SOTA with these new challenges
- Compare SOTA performance with human-like strategies
Experimental Details¶
Two Learning Challenges:
- Self-play Learning
- Ad-hoc Learning
Both with limited and unlimited sampling regimes
Self-Play Learning: Find a joint policy that maximizes a score through repeatedly playing the game.
- Sample limited regime (SL): limit the number of environment steps (turns) to at most 100 million
- Unlimited regime (UL): no restrictions on time nor computing; hence, we focus on asymptotic pefromance of scores
Ad-hoc Teams
- Mixture of agents trained each one with a particular algorithm and/or human-like
- Focus is on measuring an agent's ability to play with a wide range of teammates
Learning Agents¶
Actor-Critic-Hanabi-Agent (ACHA)
- Asynchronous implementation of an actor-critic algorithm
- Policy is represented by a DNN
- Learns a value function as a baseline for variance reduction
- Learned gradients are controlled by a centralized server, which holds the DNN parameters
- Has shown good performance on tasks such as Arcade Learning Environment, TORCS driving simulator, and 3D first-person environments.
Rainbow-Agent
- SOTA agent architecture for deep RL
- Combines innovations made to Deep-Q Networks into a sample eficient and high-rewarded algorithm
BAD Agent
- Bayesian Action Decoder
- SOTA for the two-player unlimited regime
- Bayesian belief update conditioned on current policy of the acting agent
Benchmarks¶
(that attempt to immitate human reasoning)
SmartBot
- Tracks the publicly known information about each player's cards
- Prevents other players to play/discard cards that they don't know are safe or not.
HatBot and WTFWThat
- HatBot uses a predefined protocol to determine a recommended action forall other players
- Every agent can infer other player's recommended actions according to HatBot's convention
- WTFWThat is a variant of the HatBot strategy that can play with 2 through 5 players
FireFlower
- Implements a set of human-style conventions
- Searches over all possible actions and choses the one that maximizes the expected value of an evaluation function

State-of-the-Art Results (as of 2020)¶
ACHA¶
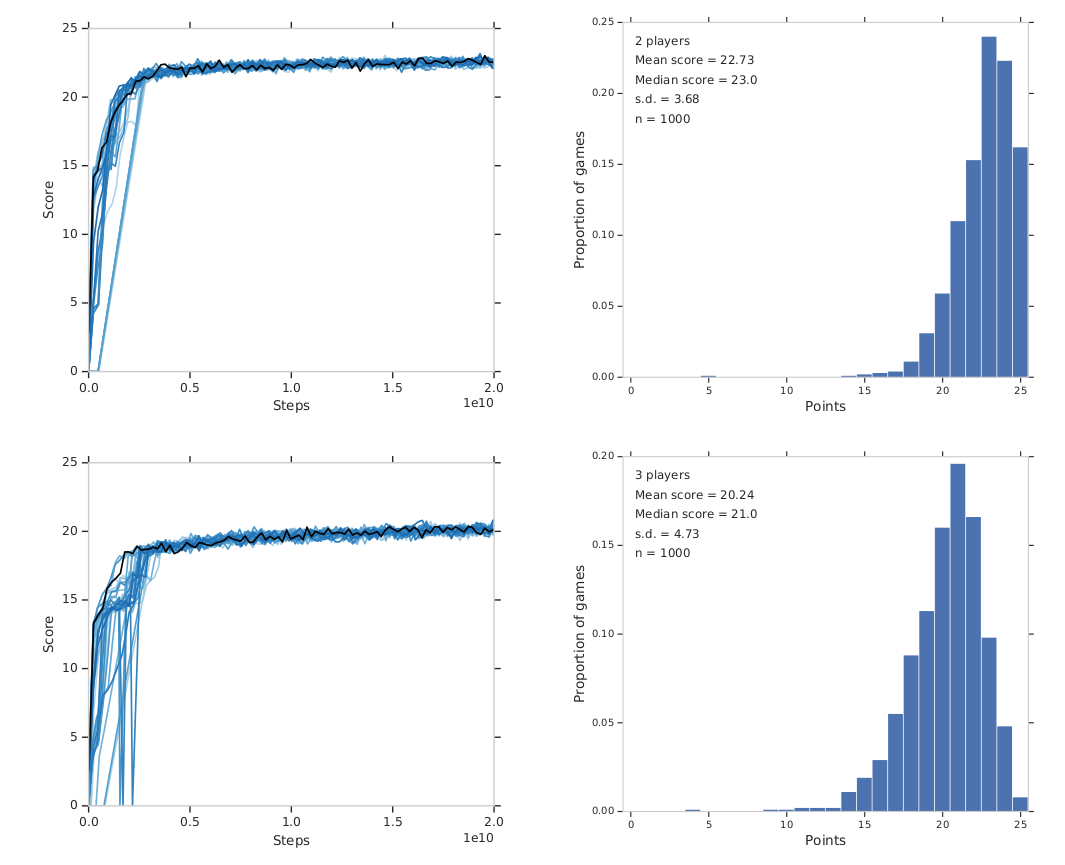
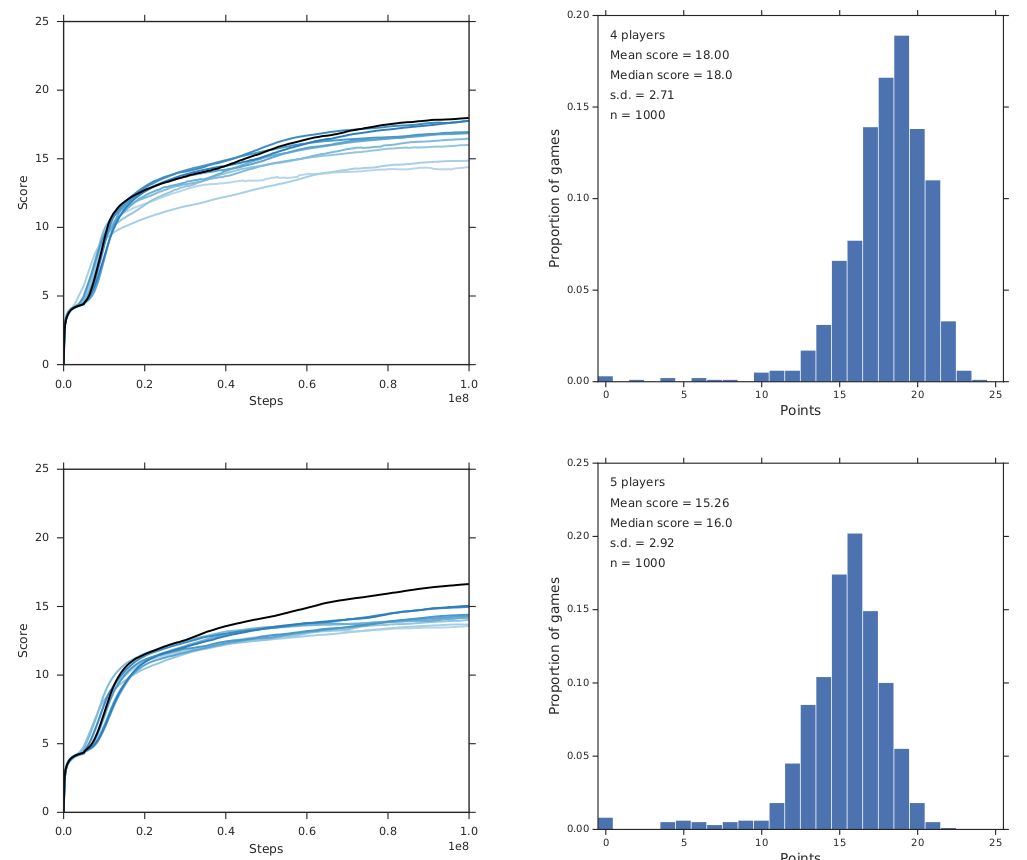
Rainbow¶
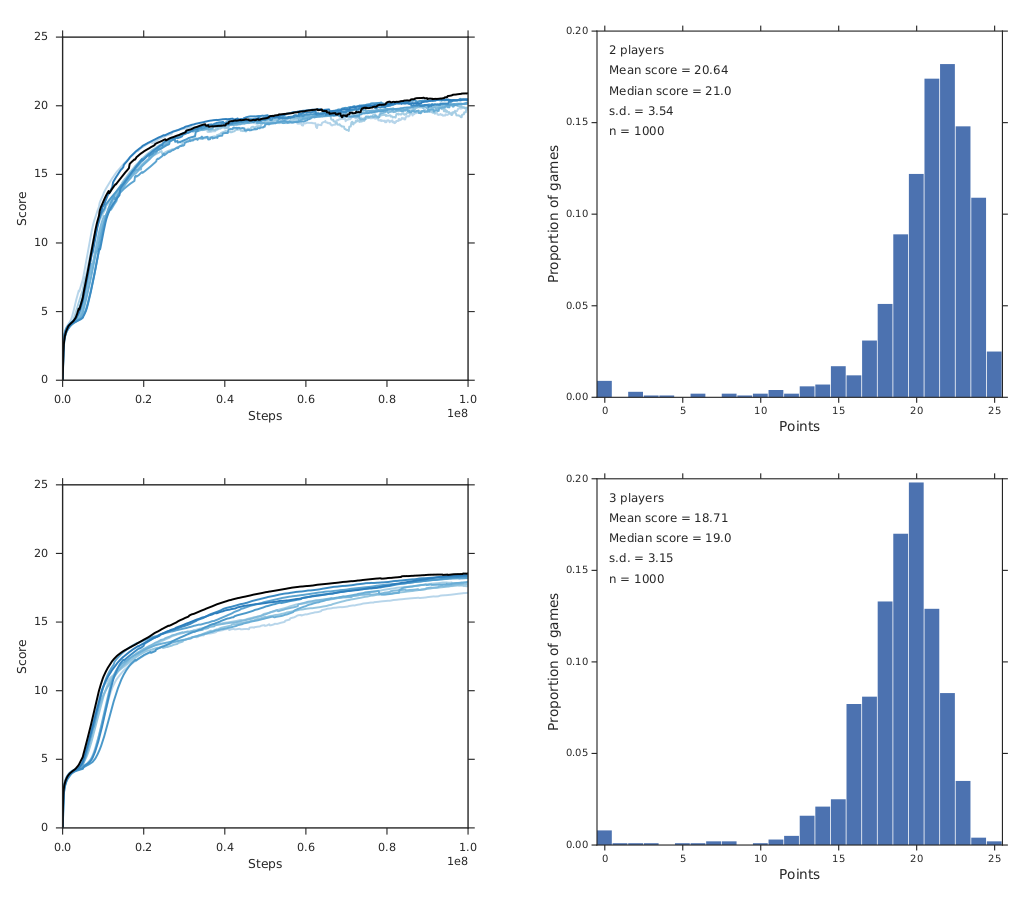
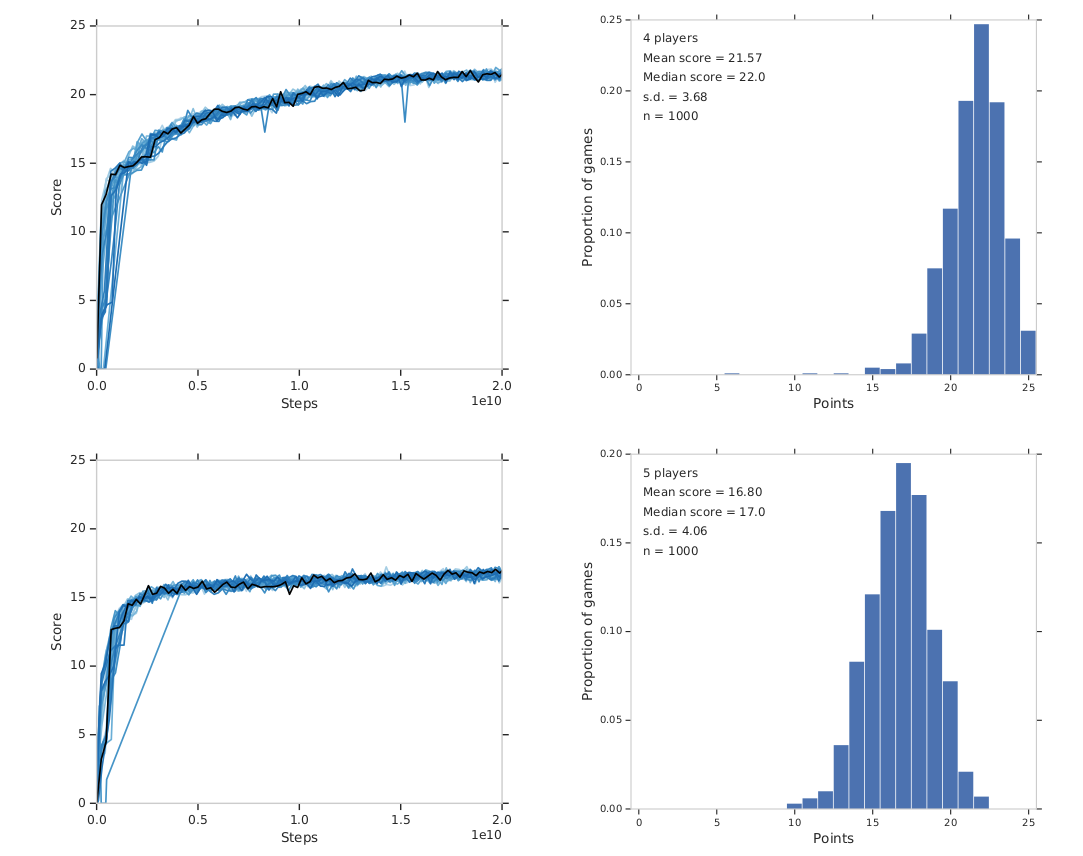
ACHA¶
Rainbow¶
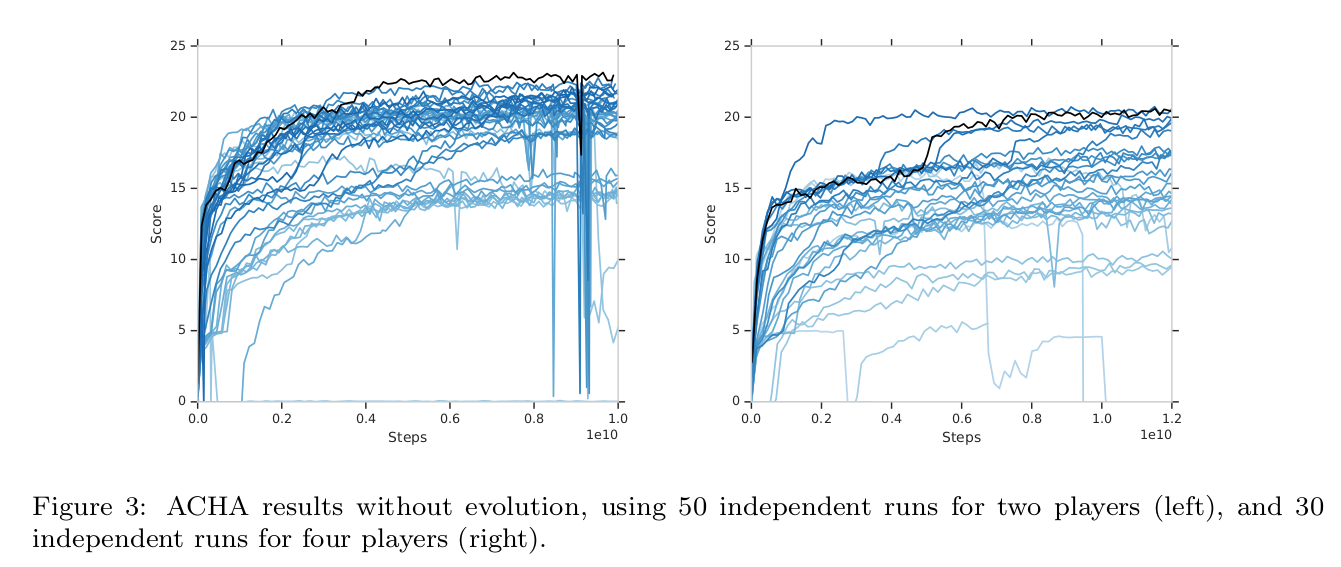
ACHA (No evolution of parameters)¶
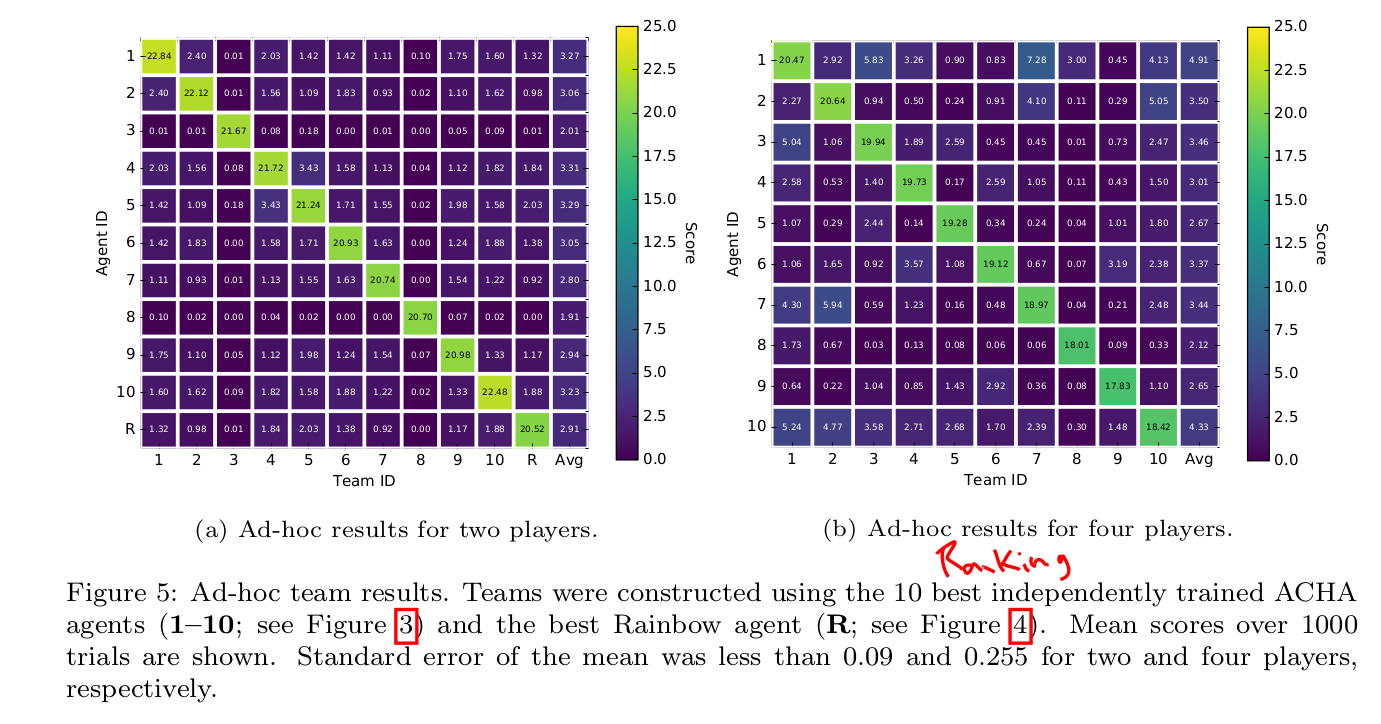
Ad-hoc team play¶
Conclusions and Future Directions¶
The cooperative gameplay and imperfect infomation of Hanabi makes it a complling research challenge for
- Multiagent RL
- Game Theory
The authors evaluate SOTA deep RL algorithms showing that
- they are largely insufficient to surpass hand-coded bots;
- in ad-hoc settings, agents fail to collaborate at all
The authors believe that theory of mind plays an important role
- to learn what humans are really thinking
- to adapt to unknown teammates
- to recognize the intention of other players
Questions?¶