On the challenges of predicting microscopic dynamics of online conversations¶
Bollenbacher, Pacheco, et al
presented by Albert Orozco Camacho
Click me to go to the article!
Motivation¶
The paper's main motivation comes from figuring out how to predict if a social media post will become viral/popular in some sort of way.
In more concrete terms:
- How can we predict the size of a conversation thread derived from a single post?
- How can we say about the structure of such conversations?
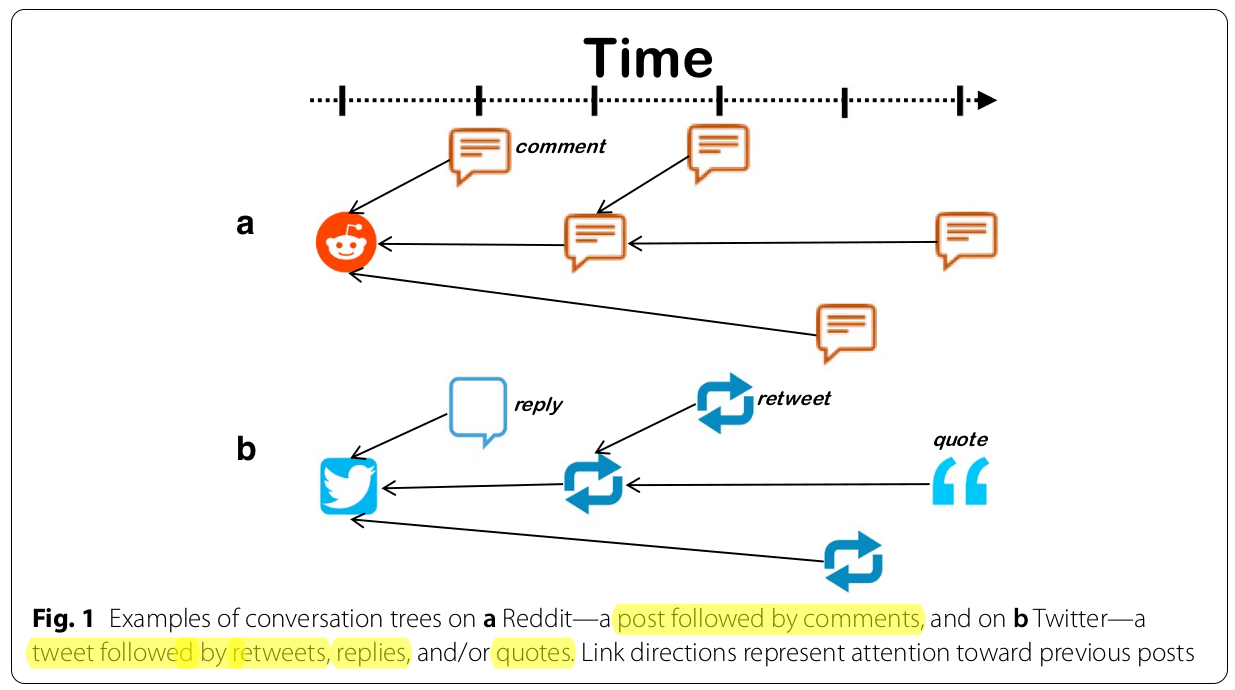
In a nutshell...¶
- The authors formalize the concept of conversation thread as a tree rooted from an initial post, (otherwise known as a cascade in other literature).
- They propose a generative model for predicting the size and structure of conversation trees:
- First predict the final size of it
- Then, inductively, add nodes to it
- Evaluate on the likelihood of correctly predicting everything (supervised)
[PERSONAL TAKE] Even though their methods use "classical ML models", their goal is rather to present a framework or template to deal with social media cascades.
Two Key Concepts¶
- Predicting macroscopic features means anything that requires the structure of a cascade as a whole.
- Predicting microscopic events functions as synonym to saying "which node follows which other"*
Modeling¶
Datasets¶
- They used 3 datasets from the 2018 DARPA SocialSim Challenge
- They are all anonymized yet NOT publicly available
- Collection of public tweet cascades that contain Common Vulnerabilities and Exposure (CVE)
- Use follower data and timestamps to reconstruct conversations
- CVE, Same as Twitter
- Also, cryptocurrency-related dataset
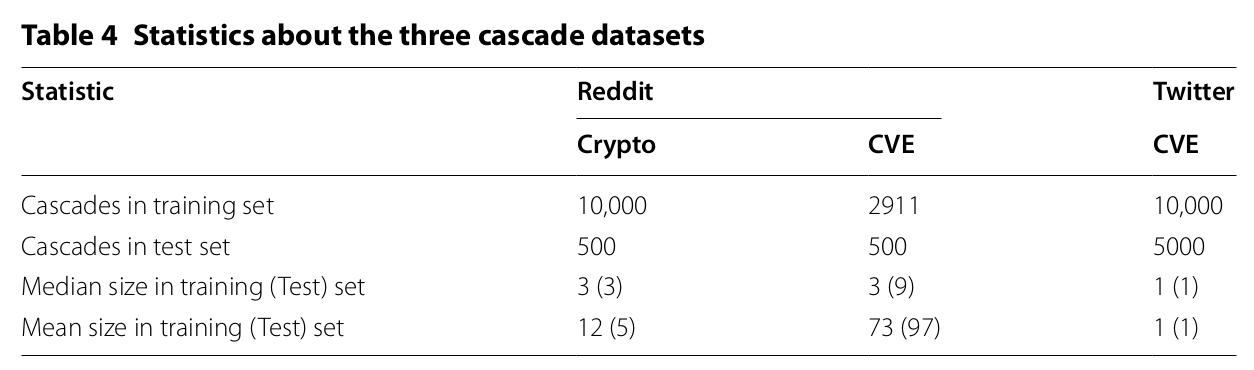
Features¶
Structural Features
- features about the current tree: initial size, depth
- features about an individual node
- parent delay relative difference in steps between a new node and its parent
User Features
- derived only from the author of the conversation's initial post
- i.e., user information
Content Features
- limited to the root of the conversation
- use of fastText, a document embedding method from FAIR
Temporal Features
- time and day of week of the root post
- not used in node placement task
Tree Growth Model (TGM)¶
Given a initial tree of $k$ nodes (possibly, $k = 1$)...
Size Prediction
- Use of regression to predicti final size of a tree.
- Based on features of the initial (partial) tree.
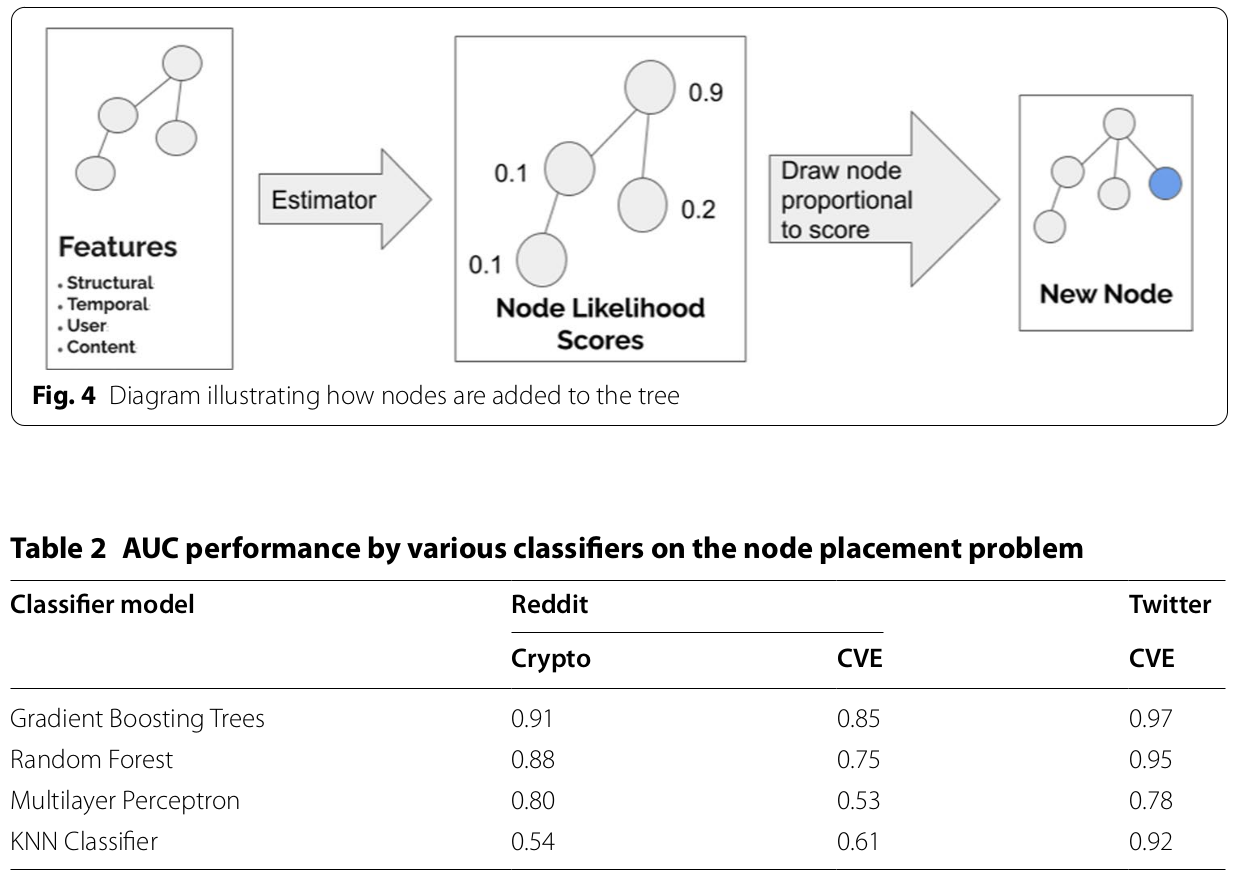
Node Placement
- Iteratively attach additional nodes to a partial tree.
- They train a likelihood estimator to assign a probability to each node in the partial tree.
- Draw a random node with probability proportional to its score.
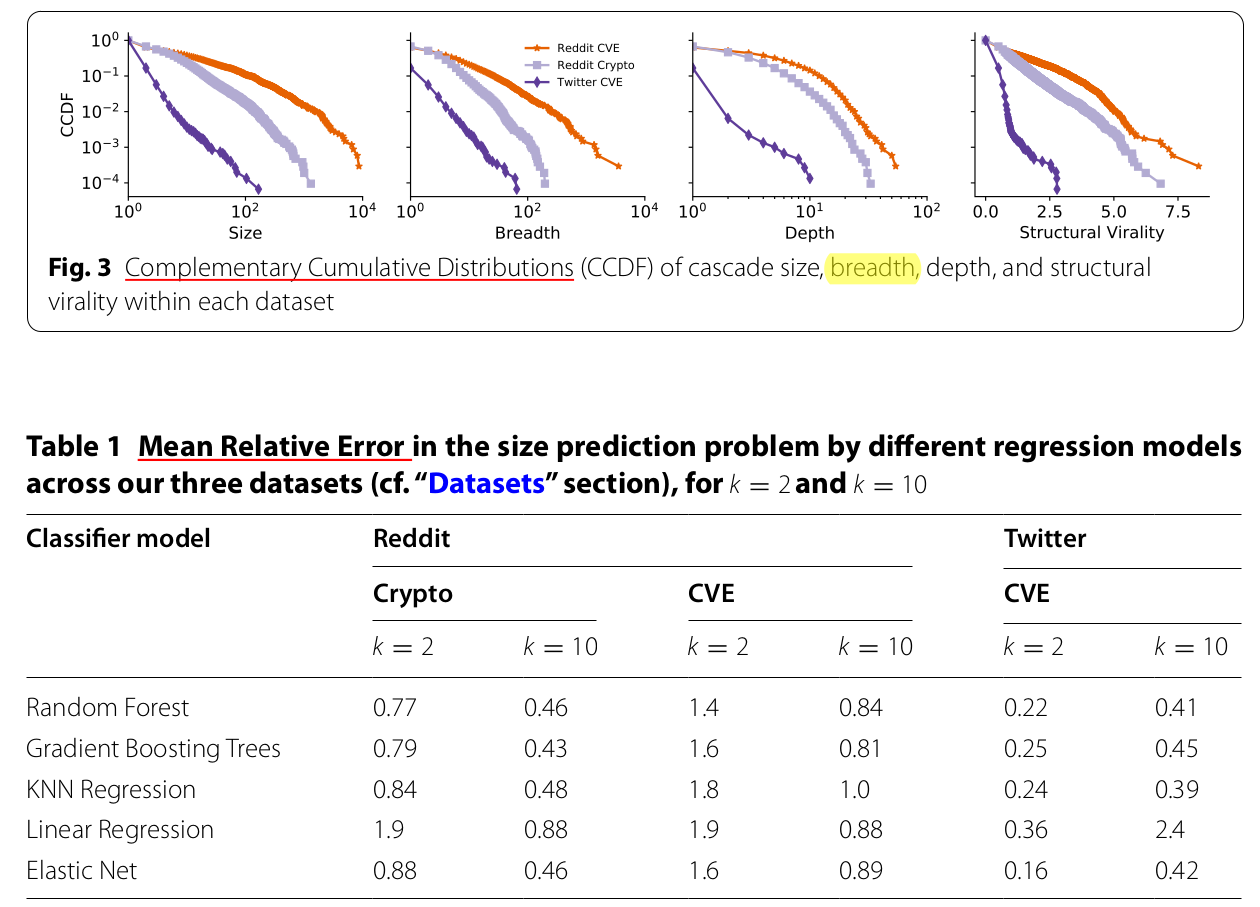
Size Prediction¶
Node Placement¶
Experimentation¶
Evaluation¶
Size Prediction
- Relative Error, calculated as $$ \frac{|s - \hat{s}|}{|s|} $$ where $\hat{s}$ is the estimated size of the tree and $s$ is the true size.
Node Placement
- Evaluated the model's ability to predict where to place the next node and compare it to random choice
- Use the probability that the correct node is assigned at each time step and use it as accuracy
Whole Tree Simulation
- Ask TGM to predict the size and structure of the final state of a conversation tree
- Evaluate on macroscopic measures: depth, breadth, virality (Wiener index)
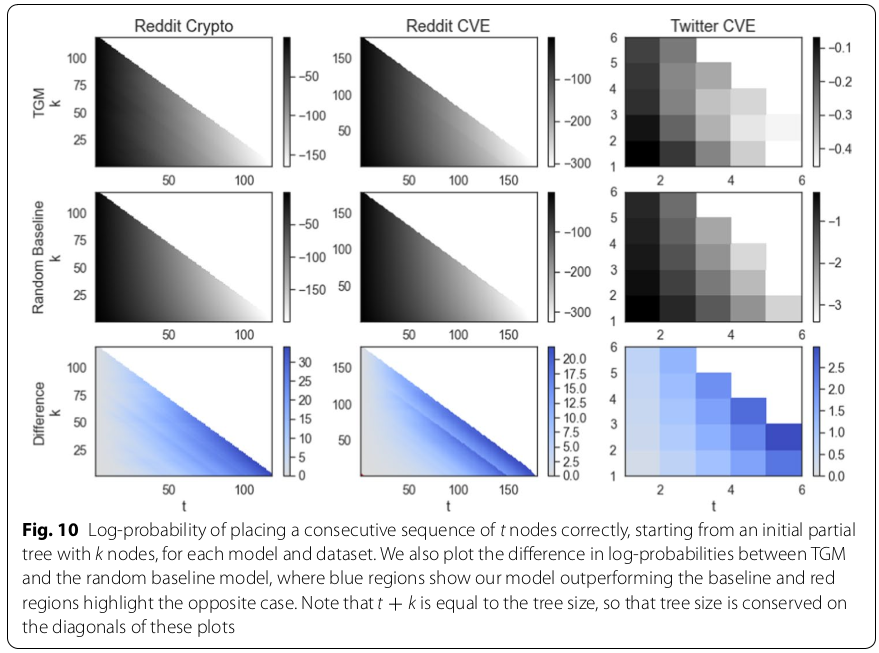
Cumulative node placement
- Probability of placing all of the next $t$ nodes correctly
- Probabilities end up being very small for large values of $t$
Results¶
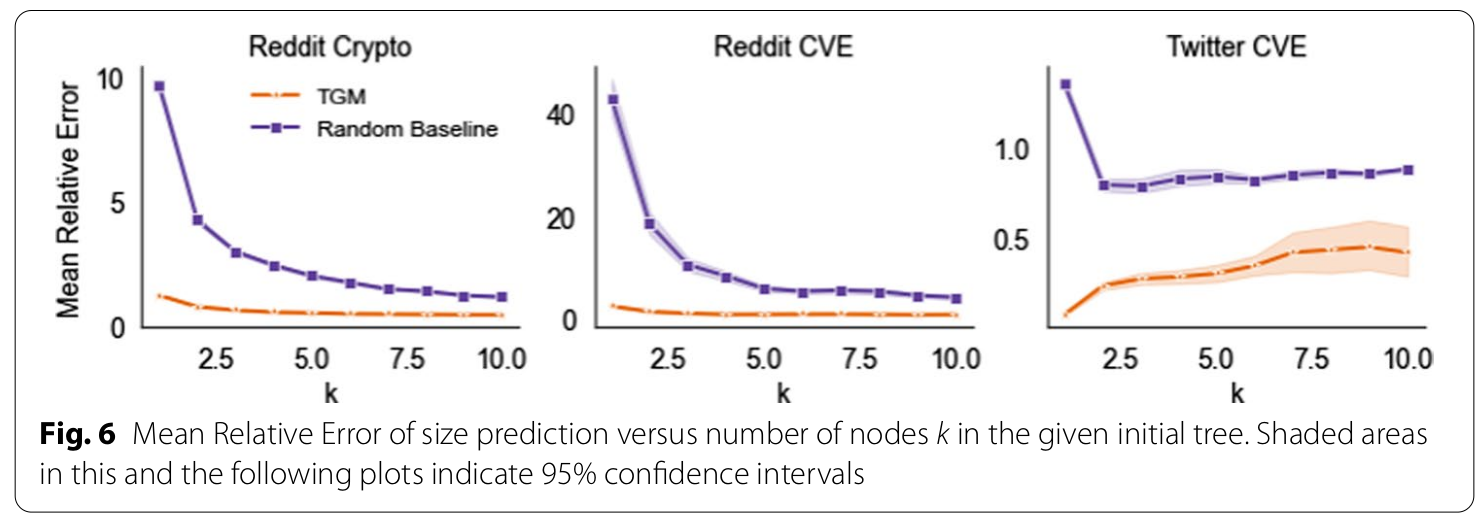
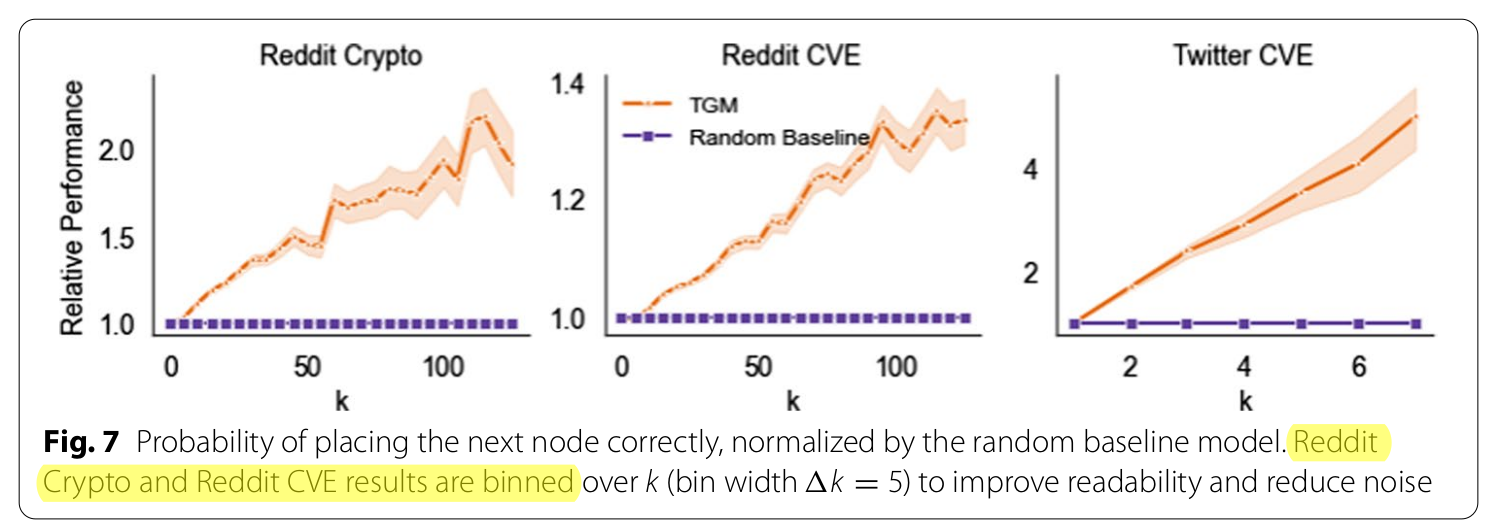
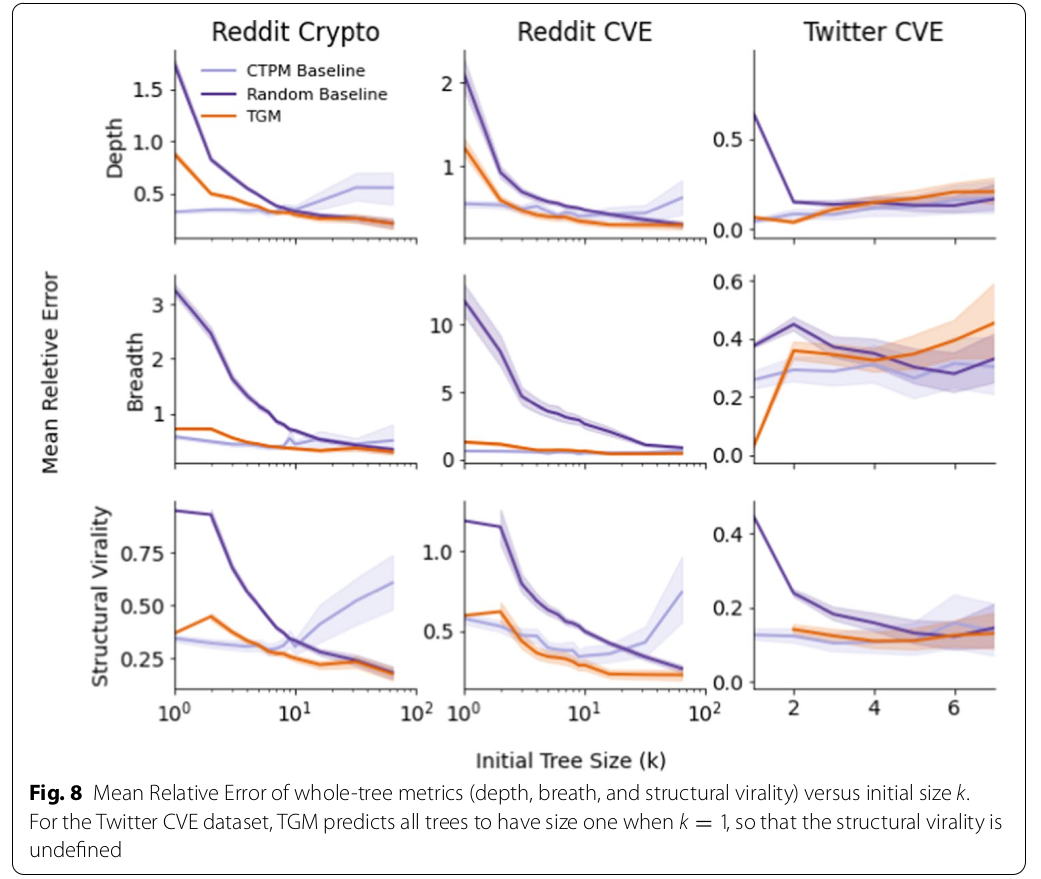
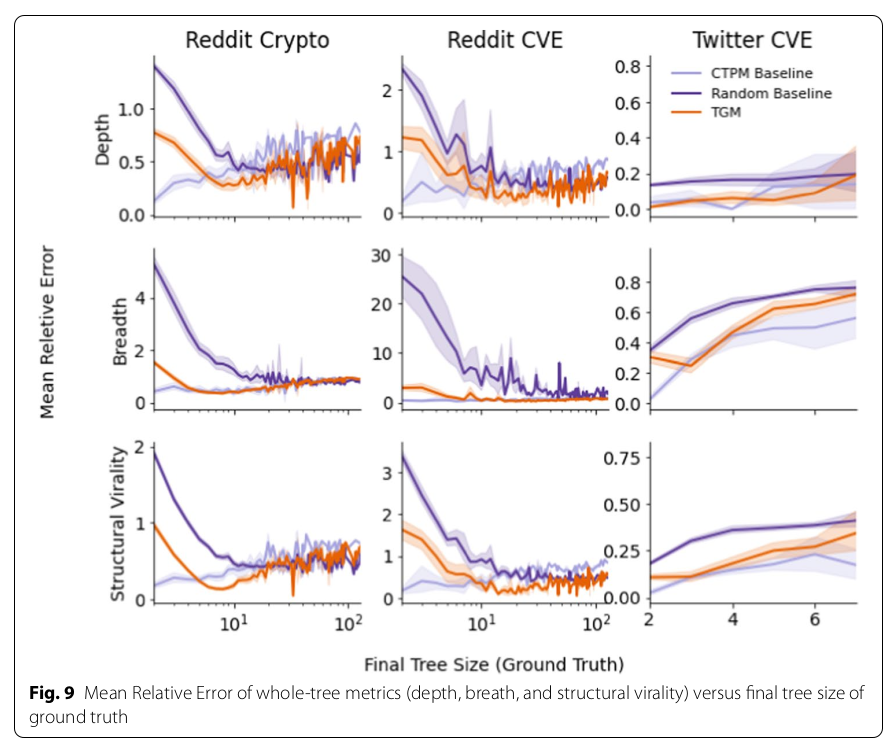
A Word (or More) on Related Work¶
There is plenty of previous work...
Cascades
- revealing common properties among popular/viral conversations; (Gómez et al. 2008; Boyd et al. 2010; Rossi and Magnani 2012; Dow et al. 2013; Weng et al. 2013)
- elusisiveness of virality prediction (Salganik et al, 2006);
Node features to
- predict macroscopic characteristics;
- describe novelty, arrival patterns, textual expression, and social influence (Backstrom et al. 2013);
- DeepCAS: predict logarithmic increments of the size of Twitter cascades (Li et al. 2017) ;
- SansNet: (based on survival analysis) predict whether cascades will become viral (Subbian et al. 2017) .
Generative modelling to
- identify underlying mechanisms that reproduce traits of cascades;
- explore reaction times and lifespans of cascades by continuous-time dynamics (Wang et al. 2012);
- examine how the structural features of conversations are affected by their presentation in a platform interface (Aragón et al. 2017);
- capture different roles in cascade formation (Lumbreras 2016; Lumbreras et al. 2017).
Deep Methods on Cascades
- CAS2VEC: embeddings from sequences of event timestamps (Kefato et al. 2018);
- predict whether users in a social graph would participate in a cascade (Islam et al. 2018);
- RNNs and temporal point processes to predict sequences of events (Du et al. 2016).
Point Processes
- simulate cascades by fitting parameters to historical data (Shen et al. 2014);
- have been successfully applied to the study of Twitter cascades (Kobayashi and Lambiotte 2016);
- CAVEAT: most point processes don't work from just the initial post.
Hawkes Processes
- predict full tree structure from only the initial post (SKrohn and Weninger 2019);
- CTPM is the only model directly comparable to the one presented in this paper!